
Skylar Shi
Email: shi.2154 at osu dot edu
About Me
I am a second year Ph.D. student in Statistics at the Ohio State University (OSU). I am also working with Xiaotian Zheng on a paper titled “Bayesian quantile regression for marked point processes.”
Before this at University of Washington, I worked with Adrian E. Raftery focused on modeling time series based on Bayesian hierarchical models and Bayesian Model Averaging, applied to global temperature forecast. Additionally, I worked with Abel Rodriguze on a one-dimensional factor analysis model, the Probit Unfolding Model, aimed at estimating individual ideology over time from binary preference data.
Manuscripts
-
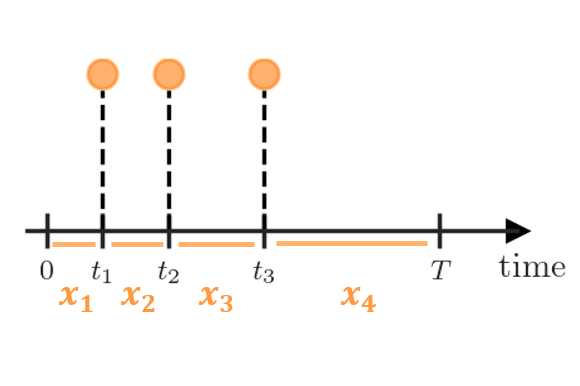 Abstract: We propose a copula-based mixture transition framework for modeling marked temporal point processes, with a focus on learning conditional quantile functions of event marks. The model represents the joint dynamics of inter-event durations and marks through a mixture of lag-specific transition components, while pair-copula constructions enable flexible modeling of non-Gaussian dependence. To capture heterogeneous effects across the mark distribution, we incorporate a quantile regression formulation based on the generalized asymmetric Laplace (GAL) distribution, allowing direct likelihood-based inference on conditional quantiles. The resulting framework provides a flexible and computationally efficient approach for modeling high-order temporal dependence and distributional heterogeneity. We establish key properties of the model and demonstrate its performance through simulations and an application to wildfire data.Keywords: Quantile regression, marked point processes, copula models, mixture transition distribution, generalized asymmetric Laplace distribution, Bayesian inference, Markov chain Monte Carlo.In preparation
Abstract: We propose a copula-based mixture transition framework for modeling marked temporal point processes, with a focus on learning conditional quantile functions of event marks. The model represents the joint dynamics of inter-event durations and marks through a mixture of lag-specific transition components, while pair-copula constructions enable flexible modeling of non-Gaussian dependence. To capture heterogeneous effects across the mark distribution, we incorporate a quantile regression formulation based on the generalized asymmetric Laplace (GAL) distribution, allowing direct likelihood-based inference on conditional quantiles. The resulting framework provides a flexible and computationally efficient approach for modeling high-order temporal dependence and distributional heterogeneity. We establish key properties of the model and demonstrate its performance through simulations and an application to wildfire data.Keywords: Quantile regression, marked point processes, copula models, mixture transition distribution, generalized asymmetric Laplace distribution, Bayesian inference, Markov chain Monte Carlo.In preparation -
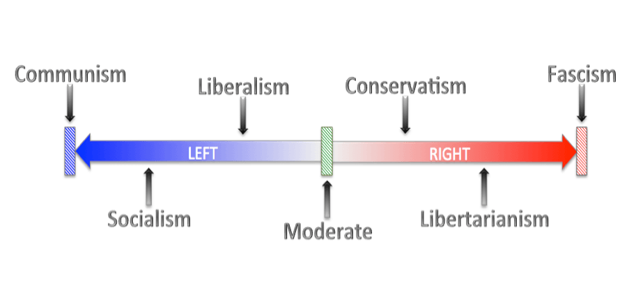 Abstract: Probit unfolding models (PUMs) are a novel class of scaling models that allow for items with both monotonic and non-monotonic response functions and have shown great promise in the estimation of preferences from voting data in various deliberative bodies. This paper presents the R package pumBayes, which enables Bayesian inference for both static and dynamic PUMs using Markov chain Monte Carlo algorithms that require minimal or no tunning. In addition to funcitons that carry out the sampling from the posterior distribution of the models, the package also includes various support functions that can be used to pre-process data, select hyperparameters, summarize output, and compute metrics of model fit. We demonstrate the use of the package through an analysis of two datasets, one corresponding to roll-call voting data from the 116th U.S. House of Representatives, and a second one corresponding to voting records in the U.S. Supreme Court between 1937 and 2022.Keywords: unfolding models, spatial voting models, non-monotonic response function, item response theory, Markov chain Monte Carlo, R, C++.Published in Journal of Open Research Software
Abstract: Probit unfolding models (PUMs) are a novel class of scaling models that allow for items with both monotonic and non-monotonic response functions and have shown great promise in the estimation of preferences from voting data in various deliberative bodies. This paper presents the R package pumBayes, which enables Bayesian inference for both static and dynamic PUMs using Markov chain Monte Carlo algorithms that require minimal or no tunning. In addition to funcitons that carry out the sampling from the posterior distribution of the models, the package also includes various support functions that can be used to pre-process data, select hyperparameters, summarize output, and compute metrics of model fit. We demonstrate the use of the package through an analysis of two datasets, one corresponding to roll-call voting data from the 116th U.S. House of Representatives, and a second one corresponding to voting records in the U.S. Supreme Court between 1937 and 2022.Keywords: unfolding models, spatial voting models, non-monotonic response function, item response theory, Markov chain Monte Carlo, R, C++.Published in Journal of Open Research Software -
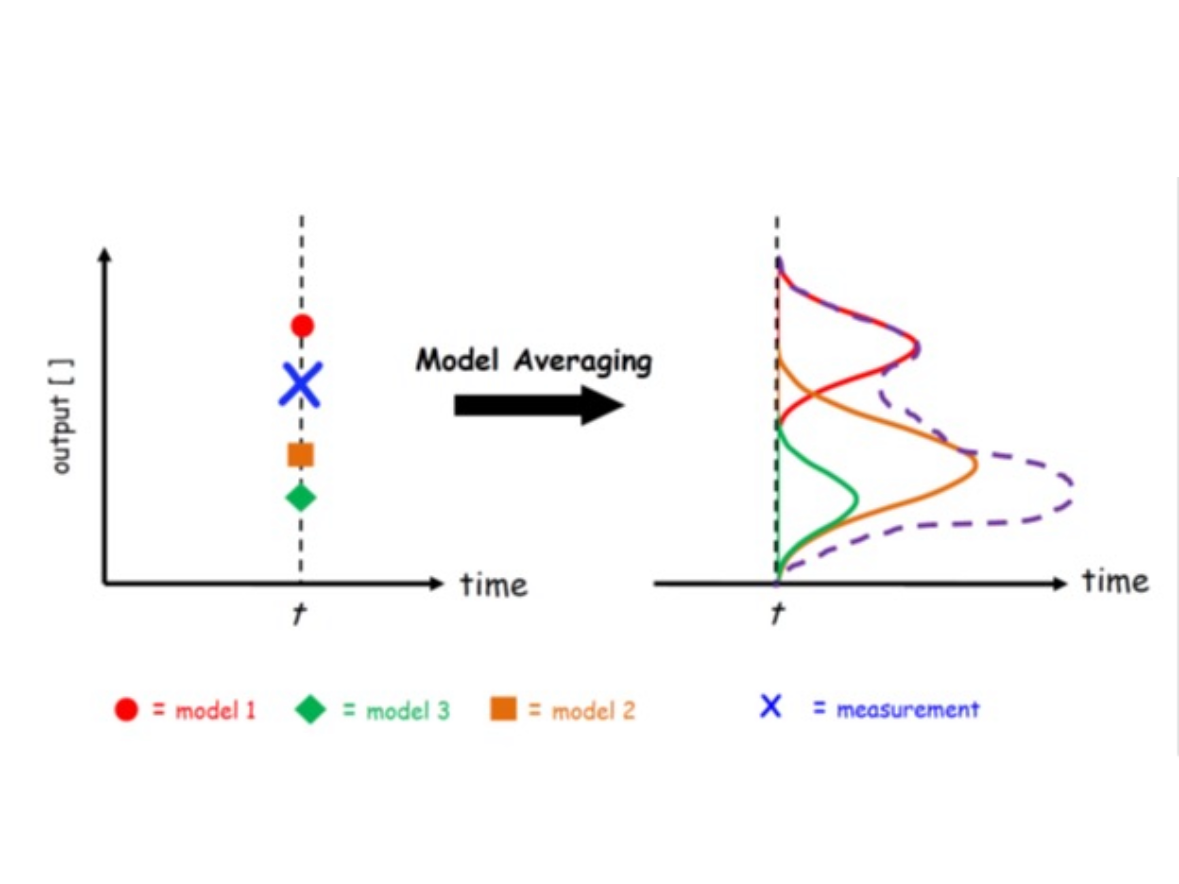 Abstract: In this study, we develop a Bayesian Model Averaging (BMA) framework to improve climate sensitivity estimation by systematically weighting Coupled Model Intercomparison Project (CMIP) models based on their consistency with historical observational data. Unlike traditional approaches that discard models with extreme equilibrium climate sensitivity (ECS) and transient climate response (TCR) values, BMA preserves ensemble diversity while probabilistically downweighting models that deviate from observational trends. We apply BMA to 51 CMIP6 models, deriving a posterior distribution for the transient climate response to cumulative CO₂ emissions (TCRE). Our results show that BMA-based projections systematically yield higher expected warming (36% increase in median TCRE) and lower uncertainty (23% reduction in variance) compared to IPCC AR6 estimates. Variance decomposition analysis reveals that parameter uncertainty in climate sensitivity contributes to 50% of total projection uncertainty, underscoring the need for improved statistical inference in climate modeling. Validation against HadCRUT5 temperature records (2015-2024) demonstrates that the BMA approach is well-calibrated and effectively captures observed temperature trends.Keywords: Bayesian model averaging, model weighting, climate sensitivity, climate projection, CMIP6.Revise and resubmit at Annals of Applied Statistics
Abstract: In this study, we develop a Bayesian Model Averaging (BMA) framework to improve climate sensitivity estimation by systematically weighting Coupled Model Intercomparison Project (CMIP) models based on their consistency with historical observational data. Unlike traditional approaches that discard models with extreme equilibrium climate sensitivity (ECS) and transient climate response (TCR) values, BMA preserves ensemble diversity while probabilistically downweighting models that deviate from observational trends. We apply BMA to 51 CMIP6 models, deriving a posterior distribution for the transient climate response to cumulative CO₂ emissions (TCRE). Our results show that BMA-based projections systematically yield higher expected warming (36% increase in median TCRE) and lower uncertainty (23% reduction in variance) compared to IPCC AR6 estimates. Variance decomposition analysis reveals that parameter uncertainty in climate sensitivity contributes to 50% of total projection uncertainty, underscoring the need for improved statistical inference in climate modeling. Validation against HadCRUT5 temperature records (2015-2024) demonstrates that the BMA approach is well-calibrated and effectively captures observed temperature trends.Keywords: Bayesian model averaging, model weighting, climate sensitivity, climate projection, CMIP6.Revise and resubmit at Annals of Applied Statistics -
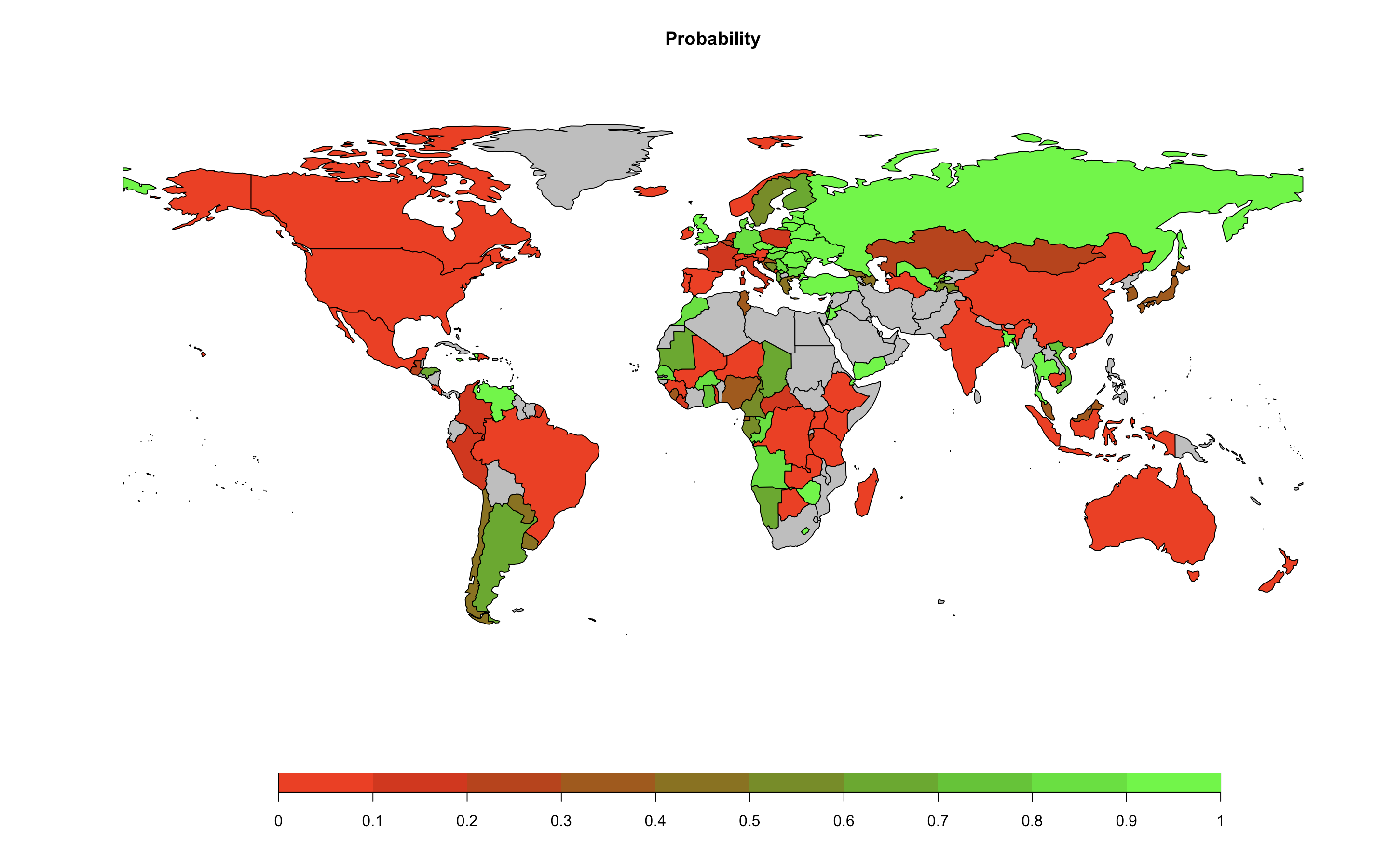 Abstract: In this paper, we employed a fully statistical probabilistic model to evaluate the likelihood of achieving the Paris Agreement’s target of limiting global temperature rise to well below 2 °C, with effort to keep it within 1.5 °C. We also conduct country-level assessments based on the nationally determined contributions (NDCs) proposed by each country to help achieve this goal. Based on current trends without additional effort, the median forecast of global mean temperature increase is 2.47 °C, and the probability of staying below 2 °C and 1.5 °C are 15.5% and 1.6%, respectively. However, if all the countries continue to reduce emissions after meeting their NDCs, the probability will increase to 52.4% and 4.6%.Keywords: Bayesian hierarchical models, global temperature projection, Paris Agreement, nationally determined contributions.Published in Communications Earth & Environment (a Nature Portfolio journal)
Abstract: In this paper, we employed a fully statistical probabilistic model to evaluate the likelihood of achieving the Paris Agreement’s target of limiting global temperature rise to well below 2 °C, with effort to keep it within 1.5 °C. We also conduct country-level assessments based on the nationally determined contributions (NDCs) proposed by each country to help achieve this goal. Based on current trends without additional effort, the median forecast of global mean temperature increase is 2.47 °C, and the probability of staying below 2 °C and 1.5 °C are 15.5% and 1.6%, respectively. However, if all the countries continue to reduce emissions after meeting their NDCs, the probability will increase to 52.4% and 4.6%.Keywords: Bayesian hierarchical models, global temperature projection, Paris Agreement, nationally determined contributions.Published in Communications Earth & Environment (a Nature Portfolio journal)